pip install XCurveQuick Start
Posted on May 31, 2022Overview
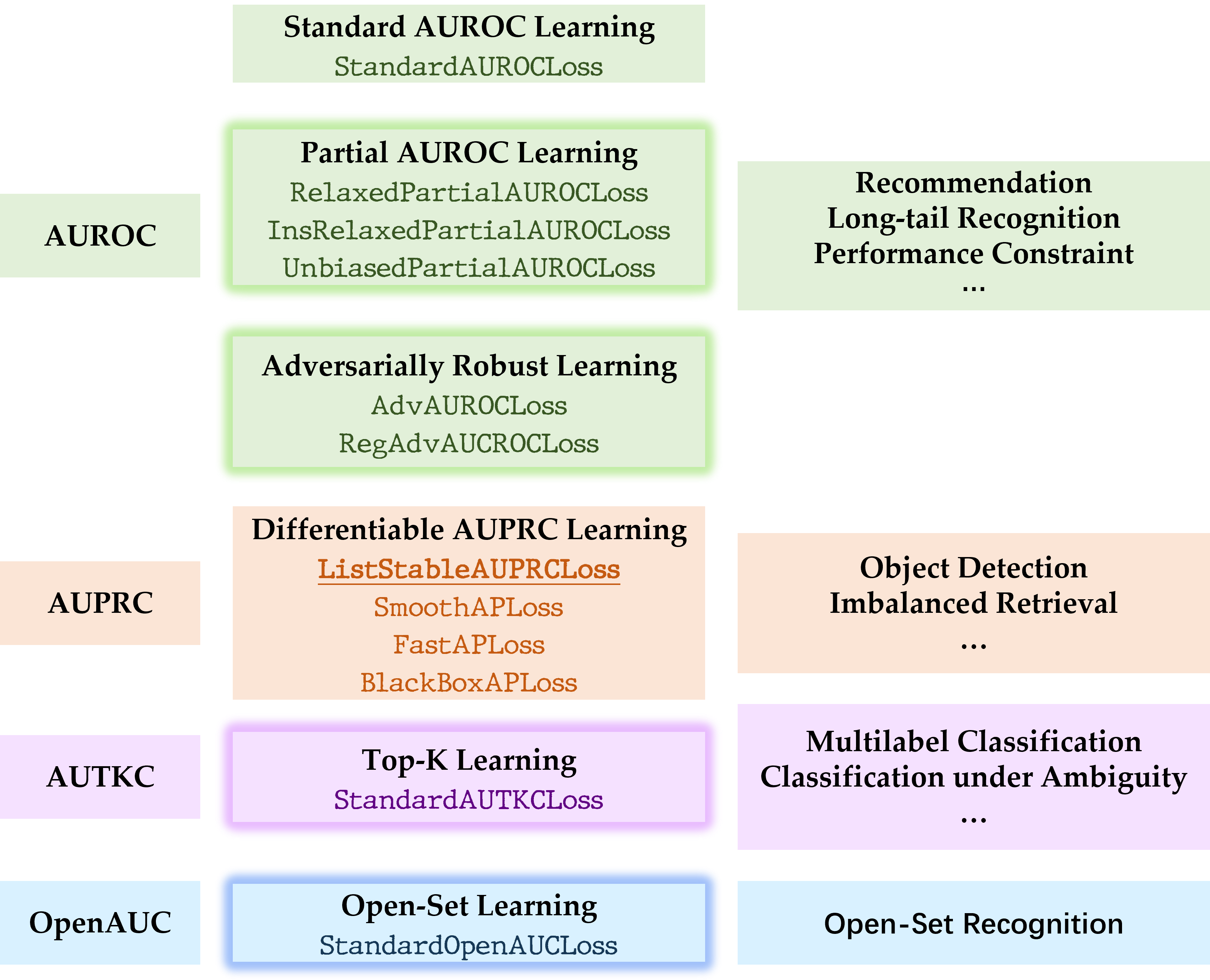
Installation
You need the following packages to install XCurve:- Python >= 3.6
- Pytorch >= 1.8.2
- Numpy >= 1.21.4
- scikit-learn >= 1.0.1
Example
'''
We refer the reader to see our paper
if they are interested in the technical details of this example.
'''
import torch
from easydict import EasyDict as edict
import torch
import random
import numpy as np
from XCurve.AUROC.dataloaders import get_datasets # dataset of Xcurve
from XCurve.AUROC.dataloaders import get_data_loaders # dataloader of Xcurve
from XCurve.AUROC.losses import SquareAUCLoss # loss of AUROC
from torch.optim import SGD # optimier (or one can use any optimizer supported by PyTorch)
from XCurve.AUROC.models import generate_net # create model or you can adopt any DNN models by Pytorch
seed = 1024
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# set params to create model
args = edict({
"model_type": "resnet18", # (support resnet, densenet121 and mlp)
"num_classes": 10, # number of class
"pretrained": None # if the model is pretrained
})
# Or you can adopt any DNN models by Pytorch
model = generate_net(args).cuda() # generate pytorch model
num_classes = 10
criterion = SquareAUCLoss(
num_classes=num_classes, # number of classes
gamma=1.0, # safe margin
transform="ovo" # the manner of computing the multi-classes AUROC Metric ('ovo' or 'ova').
) # create loss criterion
optimizer = SGD(model.parameters(), lr=0.01) # create optimizer
# set dataset params, see our doc. for more details.
dataset_args = edict({
"data_dir": "cifar-10-long-tail/", # relative path of dataset
"input_size": [32, 32],
"norm_params": {
"mean": [123.675, 116.280, 103.530],
"std": [58.395, 57.120, 57.375]
},
"use_lmdb": True,
"resampler_type": "None",
"npy_style": True,
"aug": True,
"num_classes": num_classes
})
train_set, val_set, test_set = get_datasets(dataset_args) # load dataset
trainloader, valloader, testloader = get_data_loaders(
train_set,
val_set,
test_set,
train_batch_size=32,
test_batch_size =64
) # load dataloader
# Note that, in the get_datasets(), we conduct stratified sampling for train_set
# using the StratifiedSampler at from XCurve.AUROC.dataloaders import StratifiedSampler
# forward of model for one epoch
for index, (x, target) in enumerate(trainloader):
x, target = x.cuda(), target.cuda()
# target.shape => [batch_size, ]
# Note that we ask for the prediction of the model among [0,1]
# for any binary (i.e., sigmoid) or multi-class (i.e., softmax) AUROC optimization.
# forward
pred = torch.sigmoid(model(x)) # [batch_size, num_classess] when num_classes > 2, o.w. output [batch_size, ]
loss = criterion(pred, target)
if index % 30 == 0:
print("loss:", loss.item())
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()